
GDPR in Int4 IFTT – data protection in testing

In this article you will learn how to:
– Protect production data during testing in Int4 IFTT
– Run your tests in compliance with GDPR
Introduction
The reliability of application testing results depends largely on the extent to which test data corresponds to production data. It would be best to do the tests under the same conditions as they occur in the business process and on the actual data in the company’s resources. In Int4 IFTT those conditions are met – test cases can be created based on the message that was already successfully processed in a productive environment.
But somebody may think – wait, what about GDPR (General Data Protection Regulation)? According to GDPR requirements, companies may not store or use personal data without the express consent of the person concerned. At the moment, you may ask yourself:
- How to reconcile reliable and solid tests with GDPR?
The best solution would be to perform tests with data as consistent and similar as possible to production data in a way that no GDPR rights would be broken. With automated testing tool, Int4 IFTT, you don’t have to worry about it as we are providing anonymizer feature to fill this gap.
Data Scrambling in Int4 IFTT
As mentioned in the previous paragraph, Int4 IFTT offers a functionality called message selector thanks to which you can quickly select test case data from PI/PO or CPI system without need of logging into it. Let’s assume your goal is to perform regression testing of the actual production data. Therefore, if the value is sensitive in terms of privacy or GDPR requirements, we would like to prevent the value from being stored and displayed in Int4 IFTT execution report.
Thanks to Int4 IFTT’s anonymizer feature, we can select fields which hold sensitive values and decide what action should be taken to prevent it from being compromised. Data scrambling rules are set on Automation Object level.
Procedure
To define data scrambling rules, open Int4 IFTT Mass Changes of configuration (transaction /INT4/IFTT_CONF_MASS). Select the required Automation Object and go to the Data scrambling section.
There are two rule types available:
- Test Case Creation – in case you want to scramble data during creation of a test case
- Runtime – in case you want to scramble data during runtime – when the interface is executed and additional data is loaded to test case data.
In my case, I want to protect the client’s personal data, i.e. name and address which are visible in the content of a test case:
You can decide what action should be taken to prevent it from being compromised. You can replace it with a constant, generate a GUID / random/hash value or mask it with a specific character. There is also an option to implement a custom method to meet specific scrambling criteria.
Next, specify a path that points to the field/node where the exception should be applied. It can be an xpath expression for an XML file (as in our case) or Int4 IFTT Flat File syntax for flat file formats.
In my example, I will mask each character in the name, street, and postal code with “X”. Furthermore, I’ll replace the original city with a constant value and generate a hash value using the SHA1 algorithm for the state.
Now, if we create a new test case with this automation object data scrambling rules will be applied. Result:
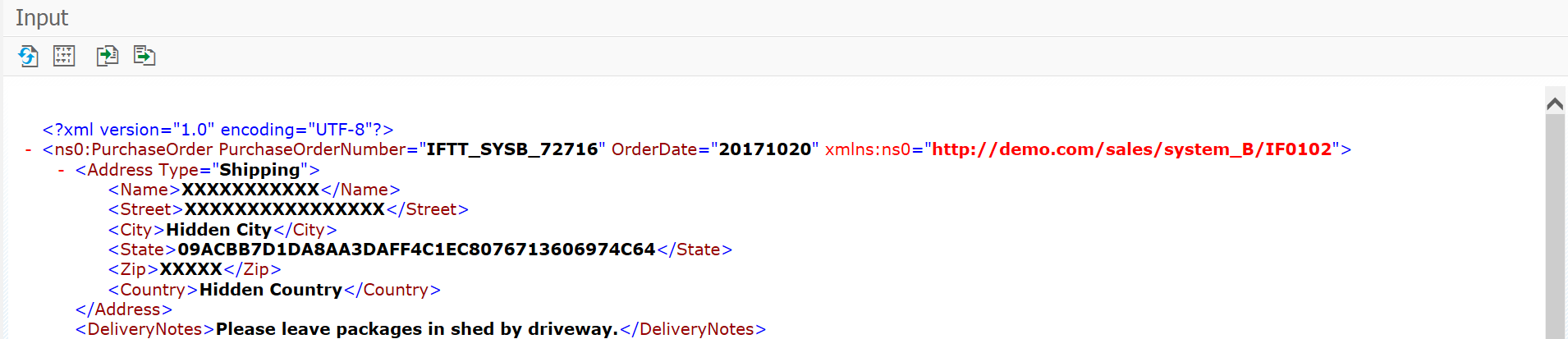
As you can see, sensitive data is not visible anymore. With Int4 IFTT anonymizer feature you can also hide data in the reference and current execution message (payloads) in a test results view:

Summary
With the Int4 IFTT anonymizer feature, you are able to prevent the value from being stored and displayed in the Int4 IFTT execution report. Therefore, you can perform regression tests based on successfully processed messages from your productive system without the risk of breaking GDPR regulations.
Read also:
Popular tags
ABAP int4 INT4 IFTT Int4Interview S/4HANA SAP AIF SAP CPI sap integration


